一、學習目標與任務定義
本日學習重點在於為 FAQ 智能客服系統建立初始環境與知識資料庫,為後續的 RAG 系統開發奠定基礎。
| 任務目標 | 狀態 |
|---|---|
| 環境整備 | 建立清晰、可維護的專案資料夾結構。 |
| 資料收集 | 蒐集一組主題明確(Google 相關)的問答資料集。 |
| 結構化 | 以 CSV 結構化格式儲存,為後續向量化與檢索(RAG 架構)準備。 |
在最後七天我想要建構一個基於 Retrieval-Augmented Generation (RAG) 架構的智能客服系統。系統將結合知識檢索與大型語言模型 (LLM),能夠從內部知識庫中檢索最相關的資訊,並生成精準、有依據的回答。
本日任務屬於專案的「資料準備與結構化」核心階段。
| 類別 | 工具/套件 | 目的 |
|---|---|---|
| 開發環境 | Jupyter Notebook | 程式碼撰寫與執行 |
| 核心處理 | os, pathlib |
專案資料夾建立與路徑管理 |
| 資料處理 | pandas |
結構化資料處理(CSV 檔案) |
| 後續元件 | FAISS, Sentence Transformers | Day 24 向量化與檢索(RAG 核心) |
採用標準的 MLOps 專案結構,有效分離資料、程式邏輯與原始碼,確保專案的整潔與可維護性。
faq_chatbot/
├── data/
│ └── google_faq.csv ← 知識庫問答資料集
├── notebook/
│ └── Day23_data_collection.ipynb
├── retriever.py ← 檢索邏輯模組 (後續開發)
├── app.py ← 前端服務 (Gradio/Streamlit)
└── requirements.txt
question(使用者詢問)和 answer(標準答案)。在 Jupyter Notebook 中執行以下程式碼,完成資料夾建立與 CSV 檔案儲存。
import os
import pandas as pd
# 1. 建立資料夾
os.makedirs("faq_chatbot/data", exist_ok=True)
# 2. 問答資料集 (部分展示)
data = [
["如何建立 Google 帳號?", "前往 https://accounts.google.com/signup 填寫基本資料即可建立帳號。"],
["忘記 Gmail 密碼怎麼辦?", "到 https://accounts.google.com/signin/recovery 進行密碼重設。"],
["如何開啟 Google 雲端硬碟?", "登入帳號後至 https://drive.google.com/ 使用雲端硬碟。"],
# ... 略 (完整 20 筆資料)
["如何刪除 Google 搜尋紀錄?", "前往 https://myactivity.google.com/ 點選刪除活動。"],
["Google Chrome 為什麼會當機?", "可能因擴充功能衝突或記憶體不足,建議更新重啟。"]
]
# 3. 轉為 DataFrame 並儲存
df = pd.DataFrame(data, columns=["question", "answer"])
df.to_csv("faq_chatbot/data/google_faq.csv", index=False, encoding="utf-8-sig")
print("✅ 已建立資料集,共", len(df), "筆問答。")
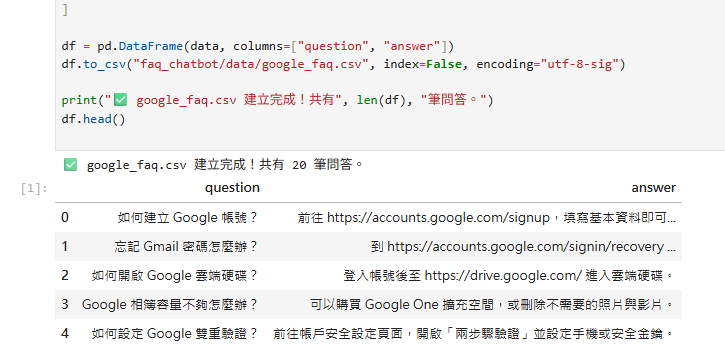
from pathlib import Path
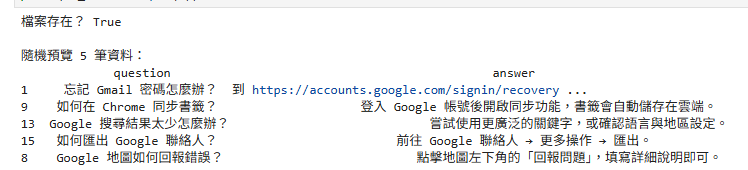
# 驗證檔案存在性
path = Path("faq_chatbot/data/google_faq.csv")
print("檔案存在?", path.exists())
# 隨機預覽資料
df_check = pd.read_csv("faq_chatbot/data/google_faq.csv", encoding="utf-8-sig")
print("\n隨機預覽 5 筆資料:")
print(df_check.sample(5))
本次題目使用大語言模型作為輔助


 iThome鐵人賽
iThome鐵人賽